About Us
Shiningsoft IT PVT LTD is a premier technology partner based in Hyderabad's IT hub. We specialize in delivering high-impact software engineering, cloud transformation, and intelligent digital solutions to global enterprises.
Please fill out the form below and we will get back to you as soon as possible.
Shiningsoft IT PVT LTD is a premier technology partner based in Hyderabad's IT hub. We specialize in delivering high-impact software engineering, cloud transformation, and intelligent digital solutions to global enterprises.
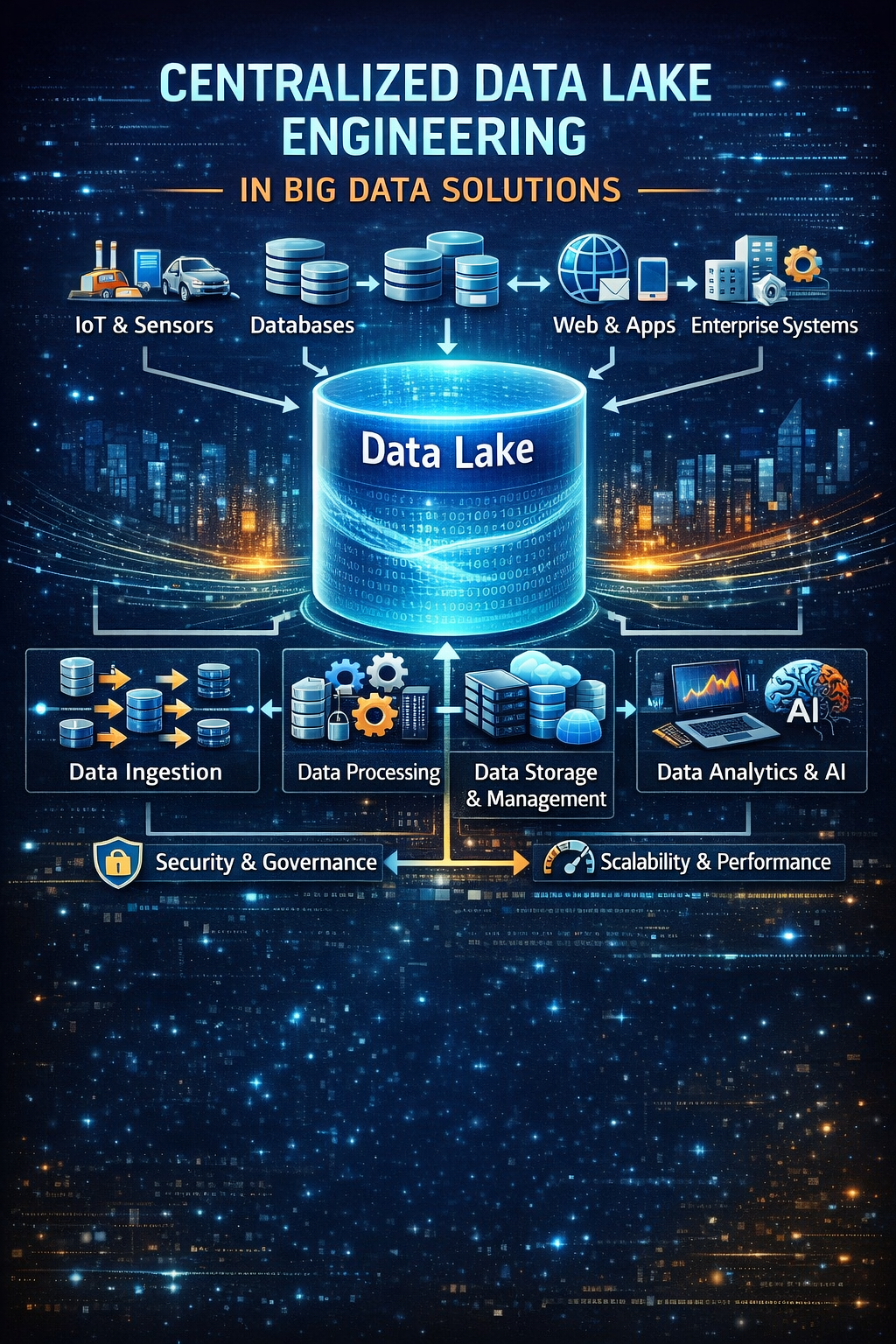
We design massive, scalable data lakes that store vast amounts of raw data in its native format. Our **Madhapur-based** architects use Hadoop, Amazon S3, and Azure Data Lake to ensure your enterprise can store structured and unstructured data without costly pre-processing.
This foundation allows your data scientists to access a "single version of truth" for advanced analytics and machine learning applications across the corporate ecosystem.
It is a central repository that allows you to store all your structured and unstructured data at any scale.
A Warehouse stores highly structured data for reporting, while a Lake stores raw data for more flexible analytics and ML.
Yes, we implement HDFS and MapReduce for large-scale on-premise or cloud-based distributed storage and processing.
Absolutely. Our pipelines can ingest millions of sensor events per second directly into the data lake architecture.

In a fast-moving market, historical data isn't enough. We build real-time data pipelines using Apache Kafka, Spark Streaming, and Flink to process data the moment it's generated. This enables instant fraud detection, live pricing updates, and immediate operational insights.
Our **Hyderabad** team ensures your streaming architecture is resilient, handling massive throughput with sub-second latency.
It is a distributed event-streaming platform used for high-performance data pipelines and streaming analytics.
Yes, our architectures are horizontally scalable, meaning we can add more processing nodes as your data volume grows.
We use decoupled architectures so that data ingestion and processing never slow down the user interface of your apps.
We implement "windowing" and "watermarking" logic in Spark/Flink to handle delayed or out-of-sequence events accurately.

We break complex computational tasks into smaller pieces that run in parallel across a cluster of servers. Using Apache Spark and Databricks, our **Spacion Towers** engineers significantly reduce the time required to run complex analytical queries from hours to minutes.
This distributed approach provides the computational muscle needed for advanced data science, large-scale financial modeling, and genomic research.
Spark processes data in-memory, making it up to 100 times faster than the disk-based MapReduce for most Big Data tasks.
It is a unified data analytics platform built on Spark that simplifies cluster management and collaboration for data teams.
Yes, we tune memory allocation and task partitioning to ensure your clusters run with maximum efficiency and minimum cost.
Absolutely. We use Spark NLP and distributed libraries to analyze massive amounts of logs, emails, and social media text.

Big Data comes with big responsibility. We implement clinical data governance frameworks that define who can access what data and for what purpose. Using tools like Apache Ranger and Atlas, we ensure your data lake remains organized, searchable, and fully compliant with GDPR and HIPAA.
We implement data masking and encryption at every stage of the pipeline to protect your most sensitive business intelligence from our **Madhapur** security hub.
It is the "life cycle" of data—tracking its origin, how it was transformed, and where it is currently stored for audit purposes.
We use automated tagging and masking to ensure that sensitive user data is only visible to authorized personnel.
It is a centralized metadata repository that helps users find, understand, and trust the data stored in the Big Data ecosystem.
Yes, we perform security and compliance gap analyses to ensure your big data practices meet international standards.
Building secure pipelines to ingest data from legacy systems, APIs, and IoT devices into a central lake at our Madhapur hub.
Cleansing and transforming raw data into structured formats using distributed computing power with clinical precision.
Running complex queries and ML models across clusters to uncover hidden patterns and business intelligence.
Delivering insights through real-time dashboards and reports that empower data-driven corporate decision-making.

We don't just build clusters; we optimize them to ensure you get maximum processing speed at minimum cloud cost.
Direct access to elite Big Data engineers and architects at our premier Spacion Towers office.
We ensure your data stays organized, compliant, and secure throughout its entire lifecycle in the cloud.

Bridging physical hardware and digital intelligence with secure smart device engineering.